

Recently I've been having a lot of conversations with enterprises where the problem of internal employee access to data has come up. Normally, we'd have robust RBAC implementations, data policies, and strong authentication mechanisms in place to ensure internal employees only got access to what they needed. But when one chatbot has access to all of the company's most sensitive data, and it's supposed to support every employee regardless of their access, people are rightfully concerned. Because the struggle isn't just about getting their generative AI model to follow instructions - it’s about ensuring that the data being shared is strictly scoped to the person asking the question. And despite the maturity of some solutions, there is still no industry-wide consensus on how to handle agent identity.
We've seen this problem before in the cloud - with The Confused Deputy scenario. The root of the problem often lies in the data layer, for most organizations internal data is rarely classified or labeled with the granularity required for an agent to be able to act upon it. So instead the internal agent, possessing high-level system permissions, inadvertently retrieves sensitive information for a low-privilege user simply because the underlying storage lacks the necessary access control metadata to stop it.
In the world of RAG and agentic workflows, identity is no longer as straightforward as a handshake. We are moving away from simple user-to-application sessions toward complex delegation chains where one to many AI agents acts as intermediaries. At Identiverse 2025, a core message was the rise of Non-Human Identity (NHI) management, and it looks to continue in 2026. As agents begin to operate with greater autonomy, the industry is realizing that existing IAM frameworks aren't ready.
Standards groups are rushing to fill this void. The IETF has seen a surge in interest regarding OAuth 2.0 On-Behalf-Of (OBO) flows specifically tailored for AI. The goal is to move beyond static service accounts and toward a system where an agent carries a cryptographically bound delegation from the user that can be used to track or authorize access downstream. This ensures that every action the agent takes is traceable back to the original user's permissions. As we look at agentic architectures with chains of AI agents, this provides traceable trust. However, much like a chain of signed certificates for websites, each agent will need to add its own digital signature, leading to problems (such as signature size) down the line.
Anthropic’s Model Context Protocol (MCP) was introduced as the "universal translator" for these interactions, aiming to standardize how models connect to tools and data. However, as organizations move into high-scale production, we’re seeing significant friction. A notable example is the shift seen with platforms like Perplexity. As detailed in a recent discussion of Perplexity’s move from MCP back toward APIs and CLIs, the "protocol-first" approach often introduces what many are calling a Context Window Tax. The overhead of carrying protocol metadata can clutter the model’s expensive reasoning budget.
More importantly, the security community is finding that standardizing authentication across a sprawl of MCP tool servers is a monumental task. Instead of an elegant, unified bridge, developers are often opting for direct API integrations because they offer more deterministic security and easier observability. When an agent calls a hardened internal API using a standard OBO token, the security team knows exactly how to audit that call. When it happens through an abstraction layer like MCP, that visibility can become opaque.
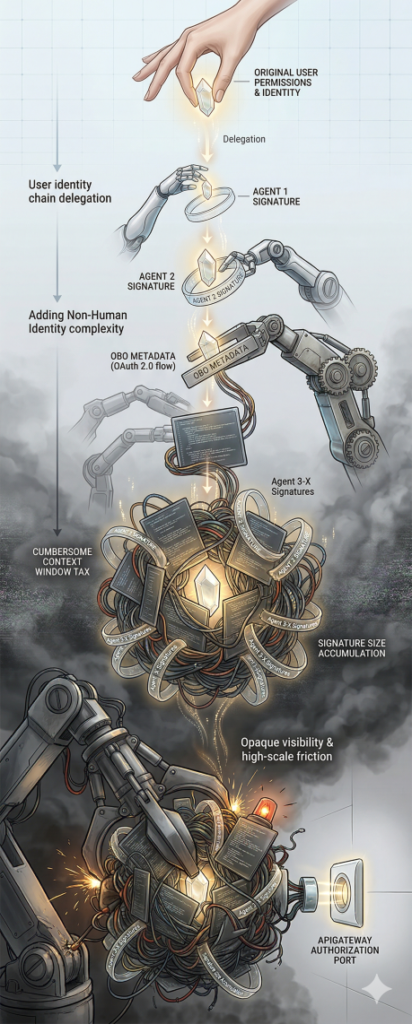
Despite the progress at the IETF and the buzz at Identiverse, agent identity remains a moving target. We are witnessing a rapid evolution of the generative AI infrastructure stack, and today’s "best practice" might be tomorrow’s legacy technical debt. As is often the case when technology isn't there yet, leaning on other controls such as governance is the best alternative. Focusing strictly on the agent's identity without having labelled data for it to access is like putting a biometric lock on a screen door. With limited resources, it's important to put what you can towards the most impactful, or regulatory compliant needs. Tracing who has accessed what is more likely to be possible given most enterprises' security posture, and if you implement that with the idea of transitioning from accountability to authorization in the future, you can save yourself a large headache.
As you navigate the complexities of agentic identity and the shifting standards of AI infrastructure, the focus remains the same: ensuring that innovation doesn't outpace your ability to defend it. If you're looking for an extra set of eyes on your AI security architecture, we’re always here to chat at questions@generativesecurity.ai.

About the author
Michael Wasielewski is the founder and lead of Generative Security. With 20+ years of experience in networking, security, cloud, and enterprise architecture Michael brings a unique perspective to new technologies. Working on generative AI security for the past 3 years, Michael connects the dots between the organizational, the technical, and the business impacts of generative AI security. Michael looks forward to spending more time golfing, swimming in the ocean, and skydiving... someday.
