
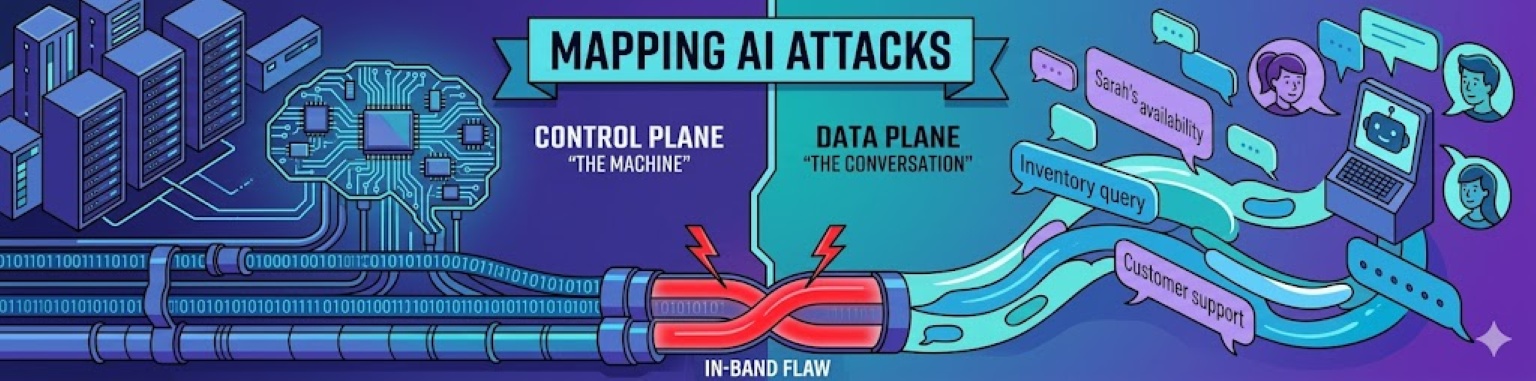
In last week's blog, "The Modern Cap'n Crunch Whistle - the in-band design flaw of LLM's", we talked about the difference between the control plane and the data plane as it related to the Plain Old Telephone Service (POTS) and generative AI. We also discussed how the combination of the two planes in an in-band system created the issues around prompt injection and jailbreaking we're seeing today. For this blog, we're going to dive into common attacks against generative AI, and look at whether they attack the control plane, or the data plane.
But why does it matter if the attacks are part of the control plane or the data plane? Because protecting the control plane does not solve for data plane problems, and vice versa. As we continue to build protections for the control plane, for agent identity, for data classification - we still need to look at how your customers interact with your chatbot. To ensure we have a consistent way of evaluating the risks across ecosystems, we’re going to use the MITRE ATLAS framework and the Cybersecurity Psychology Framework (CPF3) model in this discussion. While MITRE ATLAS does not explicitly distinguish between control plane and data plane attacks, the framework provides useful technique mappings for analyzing both.
Control plane attacks are technical attempts to interfere with the underlying system instructions of an LLM. In the context of MITRE ATLAS, these efforts represent a systematic approach to undermining a model's operational constraints. Often this process begins with User Support [AML.T0005], where an adversary probes the system to understand its logical boundaries. Once these boundaries are understood, an adversary may employ an LLM Jailbreak [AML.T0054]. Jailbreaks uses adversarial prompting to bypass built-in safety filters, moving the model into a state where it no longer strictly adheres to developer-mandated constraints.
We now arrive at the core in-band vulnerability: Prompt Injection [AML.T0051]. Because the LLM interprets user input and system instructions within the same processing window, a successful injection allows a user to provide commands that the model prioritizes over its original programming. At this point, the model isn't just failing to block a request; it is actively adopting a new set of instructions provided by the user, effectively causing the model to reinterpret or deprioritize the developer's intent.
It is important to distinguish these maneuvers from traditional machine learning threats like Evading an ML Model [AML.T0015]. While evasion is typically designed to bypass a classifier without being detected, control plane attacks are focused on redirection and command. The objective in these scenarios isn't to slip past a security layer unnoticed, but to fundamentally reprogram the agent’s decision-making logic. In an enterprise environment, the risk shifts from a model being tricked into a wrong answer to a model being instructed to ignore its security protocols entirely.


While control plane attacks focus on breaking the model's rules, data plane attacks exploit the AI’s inherent design to be helpful. These are not technical hacks in the traditional sense, but rather conversational exploits more akin to Social Engineering that leverage the model’s data access. If you think of conversational AI replacing a human in the conversation, this conversation is the data plane. As I’ve discussed in my previous look at rethinking social engineering under MITRE ATLAS, these risks often fall into a gray zone where the model is performing exactly as programmed, but the outcome is detrimental to the business or its people.
The most pervasive issue here is Contextual Blindness. Consider a customer service bot for a bike repair shop. If a user asks for the next available appointment , the model correctly identifies this as a scheduling query and may inform the user of Sarah's availability. However, if a user asks for Sarah’s availability specifically after 8:00 PM on nights when only other women are working, a human's "Spidey sense" might signal this as a safety risk. To an LLM, however, the prompt is simply a math problem. In the CPF3 framework, this moves the risk from the Cyber layer into the Personal and Physical dimensions. The system still passes all security tests because it hasn't crashed or been tricked, but it has unintentionally facilitated a physical threat to Sarah.
The chatbot's inclination to be helpful also creates significant business intelligence risks, often through "Low and Slow" data harvesting. A retail chatbot designed to confirm inventory - such as checking if two grey sweaters are in stock at a specific location - is a valuable tool for a legitimate customer. But when that same interface is used across thousands of automated sessions to scrape every size and color across every store, it becomes a tool for competitive analysis. By observing inventory changes at the start and end of a business day, a competitor or hedge fund could accurately calculate daily sales and predict quarterly earnings long before they are public. These standard prompts lead directly to data exfiltration, specifically business and operational intelligence harvesting.
Because each session used by the attacker looks like a perfectly normal customer, detection requires a few novel shifts in thinking. First, analyzing input/output pairs as part of outcome-based monitoring - where we analyze not just how the user is talking to the AI, but what the AI is ultimately handing over. Second, expanding the security analysis from single-prompt and small-content multi-prompt, to conversation-wide analysis and multi-session security analysis. This requires rearchitecting the current models into a more centralized, near-real-time approach.
The current market for Generative AI security is heavily saturated with tools designed to catch the "whistle". Most LLM guardrails and prompt-scanning solutions are built to secure the control plane. They function much like the early filters in the phone network, listening for the digital equivalent of a 2600Hz tone - looking for known jailbreak patterns, prompt injection strings, or "ignore all instructions" commands. While these are essential for preventing the technical subversion of the model, they create a false sense of security. They are designed to stop the user from hacking the machine, but they are often context-blind to the user engineering the conversation.
Thus the data plane is the critical gap in our current defensive posture. Most security tools can tell you if a user is trying to bypass a system prompt, but they cannot tell you why a user is asking for Sarah’s schedule or why they are systematically querying every sweater in your inventory. Because these interactions are polite and formatted correctly, they don't trigger traditional adversarial signatures. We need to build threat models based on intent and evaluate the resultant outputs against the derived intent associated with them. Generative AI drives this new requirement because it is replacing the human in the conversation; a human that would have these unconscious, experiential filters and triggers (aka common sense) that quickly identify malicious intent.
To bridge this gap, we must look beyond the technical layers of MITRE ATLAS and integrate the broader impact analysis of the CPF3 (Cyber-Physical-Personal-Privacy) framework. While ATLAS is excellent for mapping the Cyber techniques like Prompt Injection, it is the CPF3 dimensions that help us identify the real-world consequences of data plane exploitation. By applying CPF3, we can see how a response can lead to a Physical safety risk for staff, a Personal violation of privacy, or a Privacy breach through business intelligence harvesting. It forces us to categorize the risk not by the style of the input, but by the impact of the output.
The path forward requires a shift in how we approach AI defense. We need to move away from purely syntax and signature based filtering and toward threat modeling user intent within the data plane. We must assume that the control and data planes are permanently collapsed and design our systems accordingly. We must treat every LLM output as untrusted data and evaluate the "helpfulness" of the AI against the potential for high-scale reconnaissance. By modeling the intent behind a series of queries rather than just the syntax of a single prompt, we can finally move past the era of the Cap'n Crunch whistle and build AI systems that are resilient to both technical subversion and conversational exploitation.
Today, we are still early days on both multi-session attack analysis and user-intent driven security. But we're getting there. If you want to discuss this more or connect with us about helping you evaluate your chatbots for this type of risk, please reach out to questions@generativesecurity.ai.

About the author
Michael Wasielewski is the founder and lead of Generative Security. With 20+ years of experience in networking, security, cloud, and enterprise architecture Michael brings a unique perspective to new technologies. Working on generative AI security for the past 3 years, Michael connects the dots between the organizational, the technical, and the business impacts of generative AI security. Michael looks forward to spending more time golfing, swimming in the ocean, and skydiving... someday.
