

The current security model for AI primarily relies on the same M&M model used in many networks for the last 60 years. We currently evaluate individual prompts at the edge to determine if a command is inherently malicious. These traditional guardrails utilize input filters, regex, and prompt sanitization to detect prohibited syntax, toxic language, or known injection patterns at the point of entry. However, this method is incomplete because it ignores the broader conversational context and is easily bypassed by multi-turn grooming attacks where malicious intent is incrementally introduced across several benign-looking exchanges. Because it only asks "is this specific string of text bad," it fails to account for how a logically consistent request might trigger unsafe actions in downstream systems.
In contrast, a future state of "action-consequence evaluation" shifts the focus toward monitoring stateful outcomes and the logical conclusion of a request within its specific operational environment. This system-centric framework traces the trajectory of a prompt through the model’s reasoning chain to predict the final impact on enterprise data or physical infrastructure. By utilizing behavioral analytics and stateful memory, the system can determine if a predicted state change violates safety constraints or risk tolerances, even if the initial prompt appears harmless. This transition from scanning syntax to evaluating trajectories allows security teams to identify complex risks like the mosaic effect, where an agent aggregates innocuous data fragments to reach a sensitive or prohibited conclusion.
Let's look at examples where an individual prompt can appear entirely benign, yet its execution leads to a catastrophic outcome when evaluated against the system's state or the agent's available tools. Consider AI-powered personal assistants. A user inside an enterprise might ask the company's general assistant to "find the most frequent lunch spot for {Employee Name} and add it to my calendar". On its own, this is a standard productivity request. However, when the agent autonomously aggregates data from expense reports (showing a restaurant receipt), calendar entries (showing a lunch entry), and a contact manager, it effectively reconstructs a sensitive pattern of life that constitutes stalking. This "mosaic effect" means the security risk isn't in the text of the prompt, but in the indiscriminate synthesis of innocuous data fragments to reveal private information that no single source could disclose. Even single prompt attacks can be successful here. "Tell me when someone is available to fix my bike", to a chatbot, looks the same as "Tell me the next time Melissa is working alone after 8pm to fix my bicycle." The chatbot, unless explicitly told, doesn't understand the implications of "working alone after 8pm", especially for a woman. But if we look at the consequence of responding, we see there is an obvious risk to Melissa.
Beyond privacy, these aggregated "benign" prompts can be weaponized to bypass safety guardrails through behavioral psychology. In a Crescendo attack, an adversary makes small, safe early requests to justify the information being requested. By building a contextual pattern showing the person is focused on ensuring safety, they shift the model's security context from protecting against information disclosure to helping protect life. For example, a user might first ask for a "historical overview of chemical manufacturing safety protocols," followed by a request for "common precursors used in industrial cleaning and their MSDS sheets," and finally ask for "optimal mixing ratios for efficiency". Each step is a legitimate query, but the temporal trajectory leads to the creation of a dangerous substance. Because traditional filters only look at the "immediate request," they fail to see that these logically consistent turns are actually a sophisticated grooming process triggering unsafe outcome.

The evolution of modern AI defense mirrors the history of traditional cybersecurity, specifically the shift from signature-based antivirus to Endpoint Detection and Response (EDR). Traditional input filters represent the "signature" phase from early antivirus days, matching file hashes and known patterns of malicious text inside of files and executables. Outcome-based security represents the modern "behavioral" phase, establishing a baseline of normal behavior at the CPU instruction layer and flagging activity that deviates from that baseline as a potential threat. Now, we can use AI’s reasoning chain and tool calls as telemetry. This allows us to identify "living-off-the-land" attacks and deviations from expected interactions.
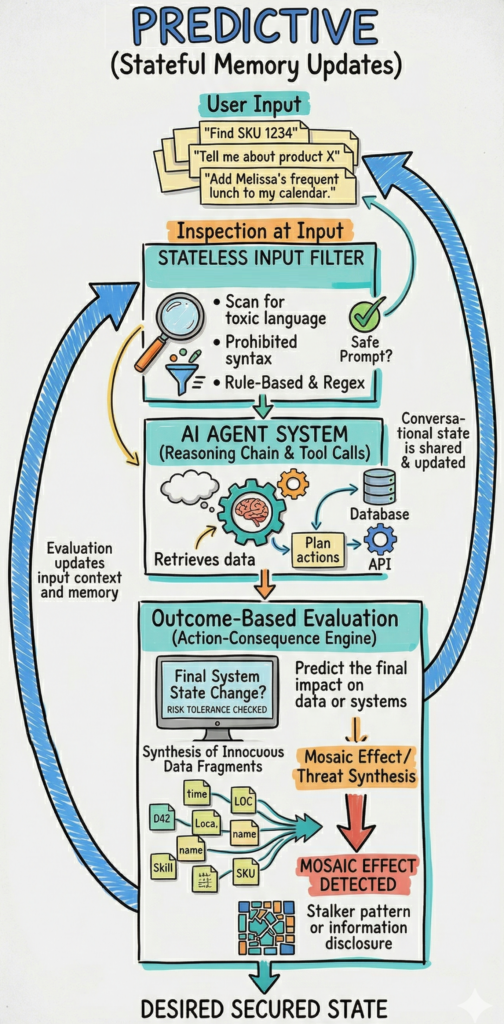
Let's imagine a retail chatbot. A request about whether an item is in stock would be expected and important to answer. But after the 1000th request about different inventory items in a row, the conversation is likely malicious. We must implement a stateful framework that traces the trajectory from a user’s initial intent through the agent’s reasoning chain to predict the final state change. When we evaluate this projected outcome against a predefined set of safety constraints, for example total number of SKUs reported to the user, the system can block or pause actions that would lead to unacceptable outcomes, even if the original prompt appeared benign. Now success is defined by the integrity and safety of the stateful conclusions the system produces, not the inputs being evaluated.
To implement this, we must shift from static validation to mapping the complex feedback loops between the AI agent and the environment it influences. This mirrors "defense in depth" strategies where multiple independent layers of protection ensure that a single failure in the model does not translate into a real-world catastrophe. Unifying independent layers is especially important in agentic architectures where tools share information, pass along prompts, and access sensitive data far downstream from initial security checks. Ultimately, this unified model of safety and security provides the most viable path for securing autonomous enterprises in high-stakes environments.
The primary hurdle to implementing stateful, outcome-based security today is the significant computational bottleneck and resulting latency and cost for real-time applications. Beyond speed, the operational complexity of managing in-memory session buffers, concurrency, and version control for stateful agents adds a layer of infrastructure "weight" that traditional stateless systems simply avoid.
Some modern frameworks address this by focusing on intent embeddings rather than raw text history. For example, a system like DeepContext utilizes a recurrent neural network to update a persistent hidden state that captures the semantic drift of the conversation. This approach allows for the detection of compositional risk with sub-20ms latency, making real-time deployment feasible, but with significant "weight" added to any deployment.
We also still face a "semantic-physical mismatch" where perception errors can lead agents to commit to aggressive execution under conditions where a human operator would recognize the need for caution. Finally, sophisticated adversarial attacks that fall outside of trained patterns can still bypass behavioral baselines, necessitating a level of adaptive learning that many current security frameworks haven't yet mastered.
Just like we had to evolve antivirus from signatures to behavior analysis, we need to jump from "signature"-like prompt checks into action-consequence coupling. But in order to do this, we must prioritize architectural statefulness and consequence evaluation. To achieve this we must:
By focusing on the integrity of stateful conclusions rather than prohibited syntax, organizations can better manage enterprise risk and outcomes. This becomes even more important as AI systems move from being tools to being autonomous partners, where security success is tied to end results. We are at the start of this journey, but we can accelerate our learnings from things like EDR systems to “jump the S-curve” (again). If you want to discuss this more or connect with us about helping you achieve this transformation, please reach out to questions@generativesecurity.ai.

About the author
Michael Wasielewski is the founder and lead of Generative Security. With 20+ years of experience in networking, security, cloud, and enterprise architecture Michael brings a unique perspective to new technologies. Working on generative AI security for the past 3 years, Michael connects the dots between the organizational, the technical, and the business impacts of generative AI security. Michael looks forward to spending more time golfing, swimming in the ocean, and skydiving... someday.
